|
|
|
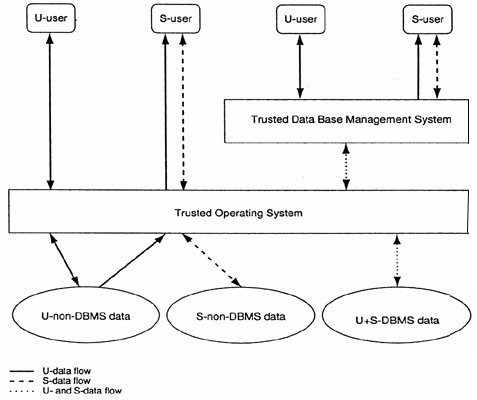
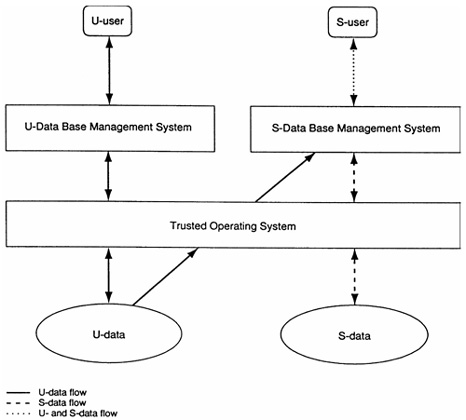
Integrated Data Architecture The integrated data architecture is illustrated in Exhibit 1. The bottom of the Exhibit shows three kinds of data coexisting in the disk storage of the illustrated systems:
At the top of the diagram on the left hand side a U-user and S-user interact directly with the trusted operating system. The trusted operating system allows these users to access only non-DBMS data in this manner. As according to the simple security and strong star properties, the U-user is allowed to read and write U-non-DBMS data, while the S-user is allowed to read U-non-DBMS data and read and write S-non-DBMS data. DBMS data must be accessed via the DBMS. The right hand side of the diagram shows a U-user and S-user interacting with the trusted DBMS. The trusted DBMS enforces the simple security and strong star properties with respect to the DBMS data. The trusted DBMS relies on the trusted operating system to ensure that DBMS data cannot be accessed without intervention by the trusted DBMS. Fragmented Data Architecture The fragmented data architecture is shown in Exhibit 2. In this architecture, only the operating system is multilevel and trusted. The DBMS is untrusted and interacts with users at a single level. The bottom of the exhibit shows two kinds of data coexisting in the disk storage of the system:
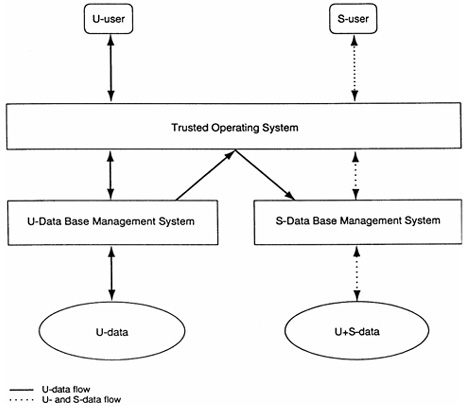
The trusted operating system does not distinguish between DBMS and non-DBMS data in this architecture. It supports two copies of the DBMS, one that can interact only with U-users and another that can interact only with S-users. These two copies run the same code but with different security labels. The U-DBMS is restricted by the trusted operating system to reading and writing U-data. The S-DBMS, on other hand, can read and write S-data as well as read (but not write) U-data. This architecture has great promise, but its viability depends on the availability of usable good-performance trusted operating systems. So far, there are few trusted operating systems, and these lack many of the facilities that users expect modern operating systems to provide. Development of trusted operating systems continues to be active, but progress has been slow. Emergency of strong products in this arena could make the fragmented data architecture attractive in the future. Replicated Data Architecture The replicated data architecture is shown in Exhibit 3. This architecture requires physical separation on backend data base servers to separate U- and S-users of the data base. The bottom half of the diagram shows two physically separated computers, each running a DBMS. The computer on the left hand side manages U-data, whereas the computer on the right hand side manages a mix of U- and S-data. The U-data on the left hand side is replicated on the right hand side.
The trusted operating system serves as a front end. It has two objectives. First, it must ensure that a U-user can directly access only the U-backend (left hand side) and that a S-user can directly access only the S-backend (right hand side). Second, the trusted operating system is the sole means for communication from the U-backend to the S-backend. This communication is necessary for updates to the U-data to be propagated to the U-data stored in the S-backend. Providing correct and secure propagation of these updates has been a major obstacle for this architecture, but recent research has provided solutions to this problem. The replicated architecture is viable for a small number of security labels, perhaps a few dozen, but it does not scale gracefully to hundreds or thousands of labels. ROLE-BASED ACCESS CONTROLS Traditional DACs are proving to be inadequate for the security needs of many organizations. At the same time, MACs based on security labels are inappropriate for many situations. In recent years, the notion of role-based access control (RBAC) has emerged as a candidate for filling the gap between traditional DAC and MAC. One of weaknesses of DAC in SQL is that it does not facilitate the management of access rights. Each user must be explicitly granted every privilege necessary to accomplish his or her tasks. Often groups of users need similar or identical privileges. All supervisors in a department might require identical privileges; similarly, all clerks might require identical privileges, different from those of the supervisors. RBAC allows the creation of roles for supervisors and clerks. Privileges appropriate to these roles are explicitly assigned to the role, and individual users are enrolled in appropriate roles from where they inherit these privileges. This arrangement separates two concerns: (1) what privileges should a role get and (2) which user should be authorized to each role. RBAC eases the task of reassigning users from one role to another or altering the privileges for an existing role. Current efforts at evolving SQL, commonly called SQL3, have included proposals for RBAC based on vendor implementations, such as in Oracle. In the future, consensus on a standard approach to RBAC in relational data bases should emerge. However, this is a relatively new area, and a number of questions remain to be addressed before consensus on standards is obtained. SUMMARY Access controls have been an integral part of relational data base management systems from their introduction. There are, however, major weaknesses in the traditional discretionary access controls built into the standards and products. SQL’89 is incomplete and omits revocation of privileges and control over creation of new relations and views. SQL’92 fixes some of these shortcomings. In the meantime such vendors as Oracle have developed RBAC; other vendors, such as Informix, have started delivering products incorporating mandatory access controls for multilevel security. There is a recognition that SQL needs to evolve to take some of these developments into consideration. If it does, stronger and better access controls can be expected in future products.
|